





AI(人工知能)
DALL-E 3とは?使い方と生成例 – 画像生成AIの決定版となるか!?
- 最終更新日:



DALL-E3はChatGPTの開発元であるOpenAI社が開発している画像生成AI機能のサービス名で、テキストによる指示文を元に画像を生成してくれます。隣に配置しているアイキャッチ画像の背景はDALL-E3で生成したものです。
DALL-E3は、作成して欲しい画像を日本語で文章で入力すると数秒のうちにAIで画像を生成してくれるというもので、非常に細かい描写のCGを作ってくれたりと、初めて使う人は驚くであろう性能をしています。
この記事では、DALL-E3がどのような画像を生成してくれるのかと、使い方、他の画像生成AIとの比較を行います。
※ ChatGPT Plusにおいては、DALL-E3のリリース当初、指示に対して4枚の画像を出力してくれていましたが、2024年1月時点で、1枚に変更されました。 この記事では、4枚出力されたときのものをベースにご紹介しています。
DALL-E3とは?
DALL-E3は、2023年9月21日(現地時間)に、OpenAI社がChatGPTに追加すると発表した画像生成AIです。使い方は非常に簡単で、作成して欲しい文章を書いて指示をするだけです。日本語にも対応しています。「DALL-E3」の読み方は「ダリ・スリー」となります。「DALL」の「E3」ではなく、「DALL-E」の「3」なのです。「DALL-E」を「ダリ」と読みます。「ダリ―」と読む人もいます。
「DALL-E3」は、前のバージョンである「DALL-E2」と比べて、大幅に性能が向上しました。
DALL-E3以外の画像生成AIとしては、Midjourney(ミッドジャーニー)とStable Diffusionが有力で質の高い画像を生成してくれるのですが、少し使い方が難しいという難がありました。これらに比べて、DALL-E3はとにかく作成して欲しい画像を文章で表現するだけで良いので、多くの人が今後DALL-E3を使うようになると思われます。
DALL-E3を使う3つの方法とそれぞれの使い方
DALL-E3を利用する方法は現在、大きく3つあり、そのうちBingを利用する方法の場合、生成画像の商用利用はできないので、その点は注意が必要です。
リテラ(BringRitera)でDALL-E3を利用する方法
リテラ(BringRitera)は株式会社BringFlowerが開発・運営しているツールで、月額550円(税込)~でDALL-E3を使うことができます。Bingとは違い、商用利用可能です。
フリープランもありますが、画像生成の機能を用いるにはライトプラン(月額550円)以上に申し込む必要があります。とはいえ、後述するChatGPTでは月額20ドルが必要なので、それよりも安くてお得ですし、かつ使い勝手がChatGPTよりも良いのでおすすめです。
まずは「無料で使ってみる」を押してユーザー登録をしたのちに、有料プランに申し込みをします。
そうすると、「画像生成」のメニューにアクセスできるようになります。
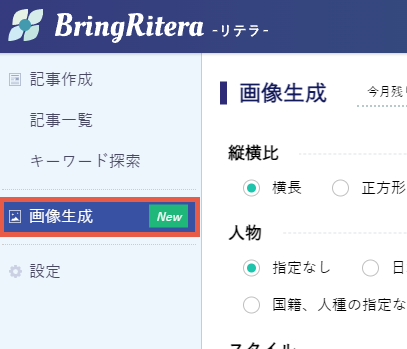
画像生成時、文章での指定以外に、縦横比、人物、スタイルをそれぞれ選ぶことができます。これらは「設定」でデフォルト値を変えることもできます。
後述するChatGPTの場合、人物は文章で指定しない限り、日本人が描かれるとは限らなかったりもして、その指定を忘れてしまうこともあるので、便利な機能です。
また、ChatGPTの場合、「日本人」と指定すると着物姿だったり、昔の日本を描いてくることが多いのですが、BringRiteraではそのようなことも少なくなります。

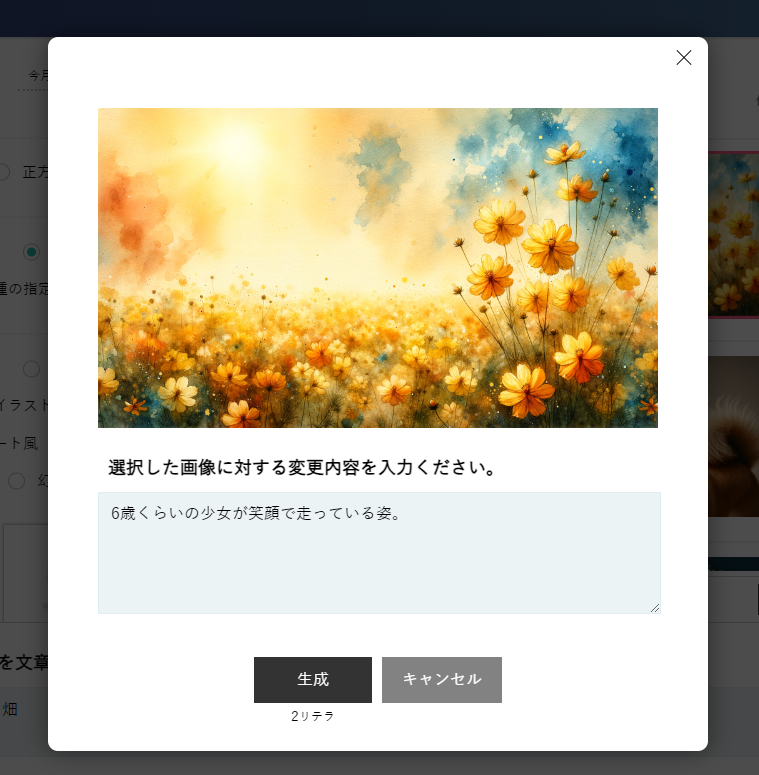
あとは、文章による指定を入力し、出力する枚数を選んで「生成」ボタンを押せば生成されます。
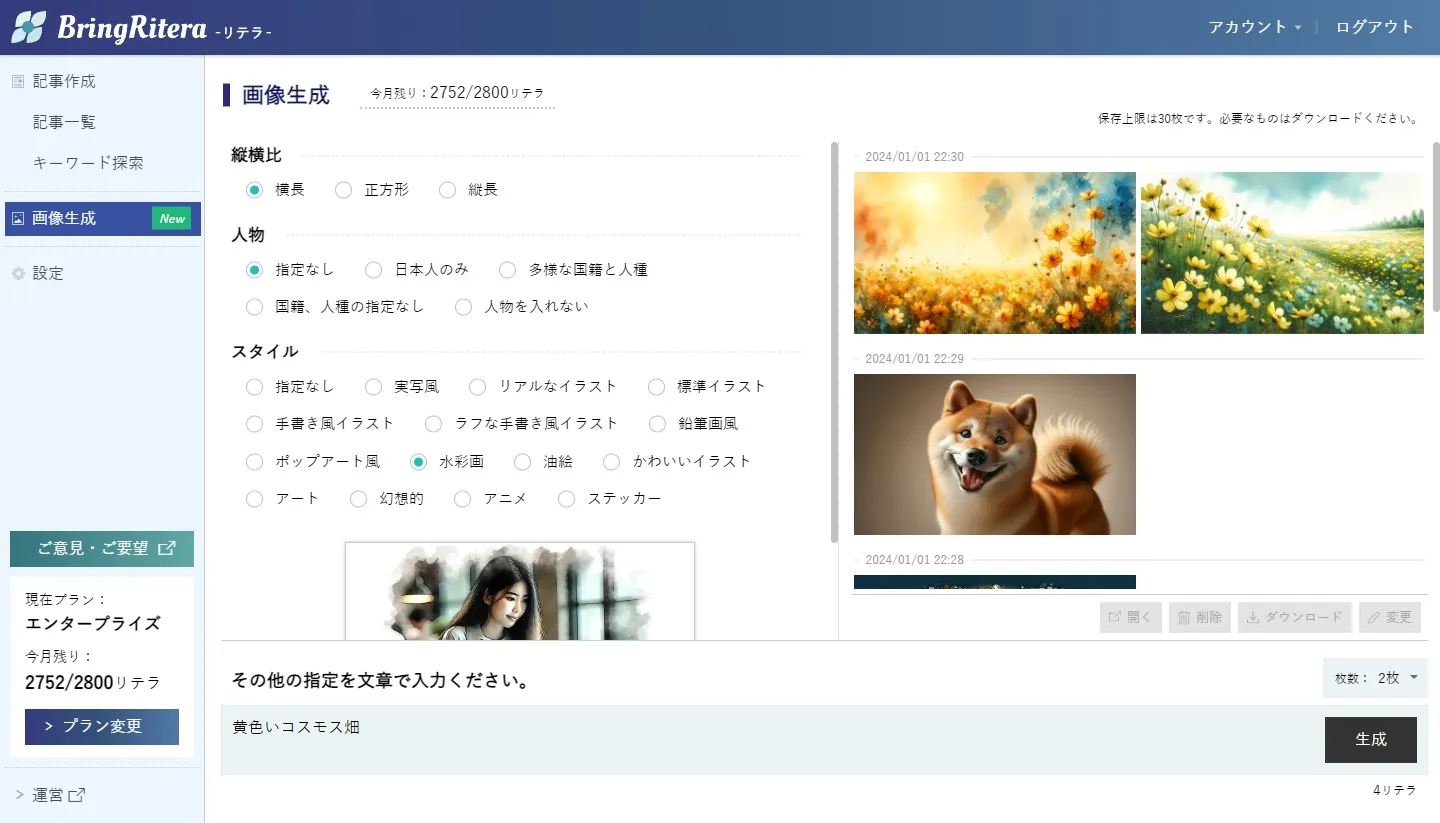
画像を開いて表示すると、画像が大きく表示されると共に、実際に使われたプロンプトも表示されます。
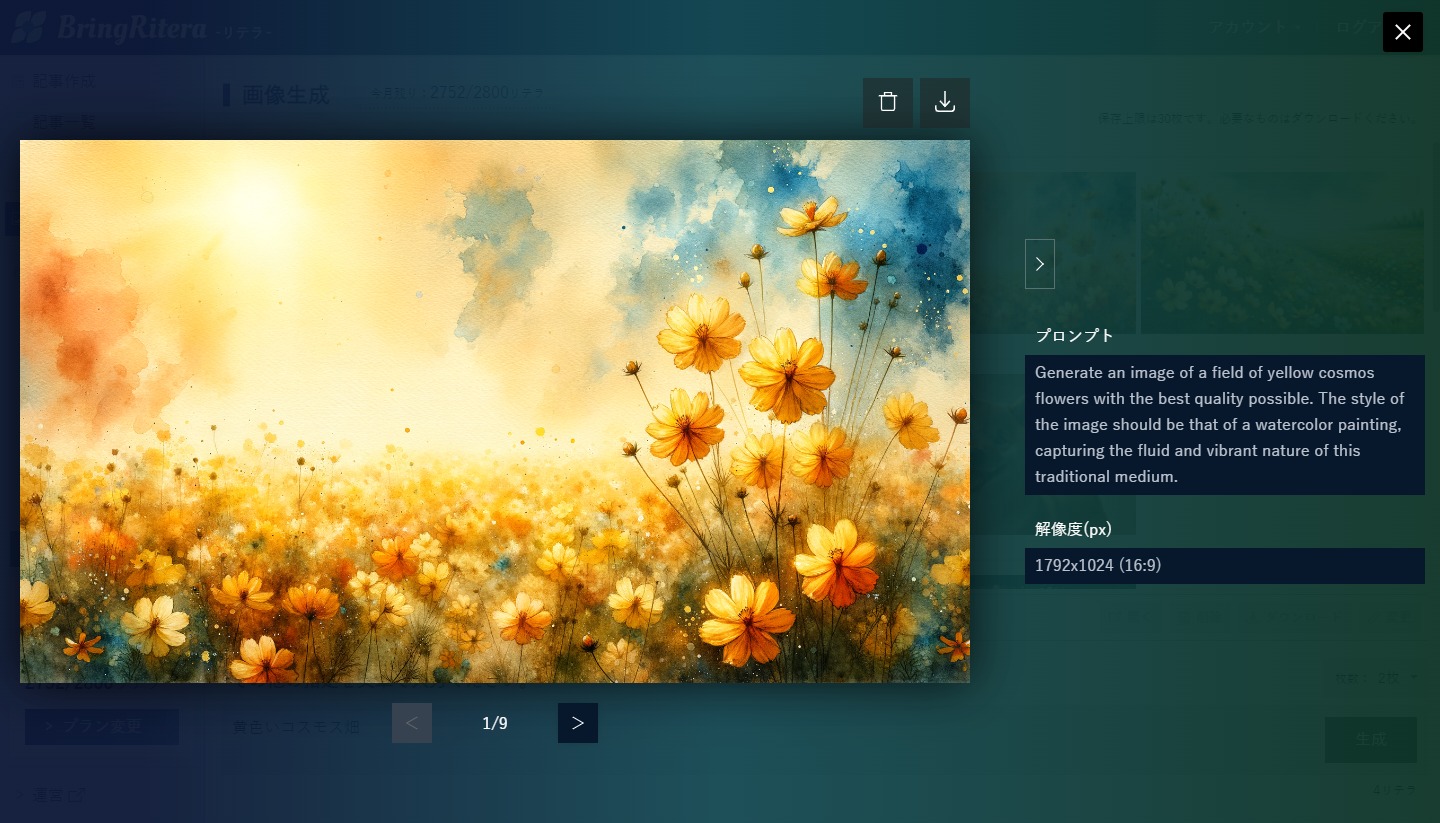
画像を選択後、「変更」ボタンを押すと、その画像に対しての変更点を指示することができる機能も便利で、ChatGPTにはない機能です。ChatGPTも変更指示を出すことはできますが、指示を出した部分以外も大きく変えてしまうことが多いのに対して、BringRiteraはベースの画像を維持しつつ、変更指示を反映してくれます。

リテラ(BringRitera)は2024年8月にFLUX.1 [pro]とStable Diffusionシリーズにも対応し、様々なAIモデルが利用できるようになりました。詳しくは次の記事で紹介しています。
ChatGPTでDALL-E3を利用する方法
DALL-E3を開発しているのはChatGPTを開発しているOpenAI社であり、月額20ドルのChatGPT有料版「ChatGPT Plus」あるいは法人版の「ChatGPT Enterprise」を利用していれば、DALL-E3を利用することができます。
ChatGPT Plusでログインすると、上部にChatGPT-3.5とChatGPT-4を切り替えるプルダウンが表示されます。そこでChatGPT-4を選択し、あとは「~の画像を作成して」のような文章を入力するだけです。
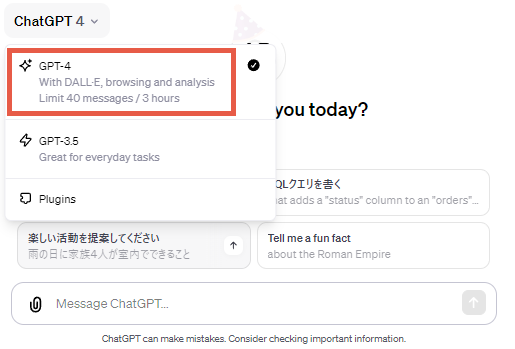
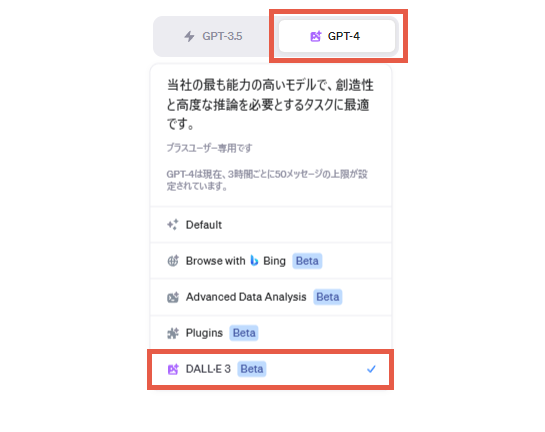
なお、登場した当初は次のようにDALL-E3を利用するという宣言を行わなければ使えませんでしたが、今は指示文だけで画像を作成する指示なのかどうかが判別してもらえます。
BingでDALL-E3を利用する方法
MicrosoftはOpenAI社に多額の投資をしてきているので、Microsoftの検索エンジンであるBingでChatGPTを早い段階から利用できるようになっていましたし、DALL-E3も無料で利用することができます。ただし、Bingによる生成画像の商用利用はできないので、その点はご注意ください。
また、BingでDALL-E3を利用するには、MicrosoftのブラウザであるEdgeを利用する必要があります。EdgeでBingを表示させ、チャットモードにします。チャットモードへの入り方はいくつかあります。Bingのホーム画面からの場合、検索窓右側のマークあるいは「新しいBingとチャットする」を選択します。
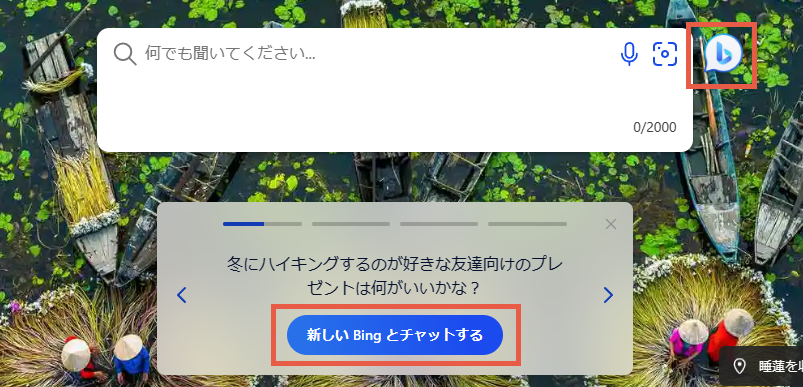
チャットモードに入ったら、あとは生成して欲しい画像をプロンプトで指示するだけです。
DALL-E3で生成できる画像とプロンプトの例
それでは、どのようにプロンプトを入力するとどのような結果が返ってくるか、「ChatGPT Plus」の画面を使ってご紹介していきます。
デフォルト
「ITをイメージさせるような画像を作成して」と入力した場合が次の例です。このように、デフォルトでは正方形の画像が作られます。
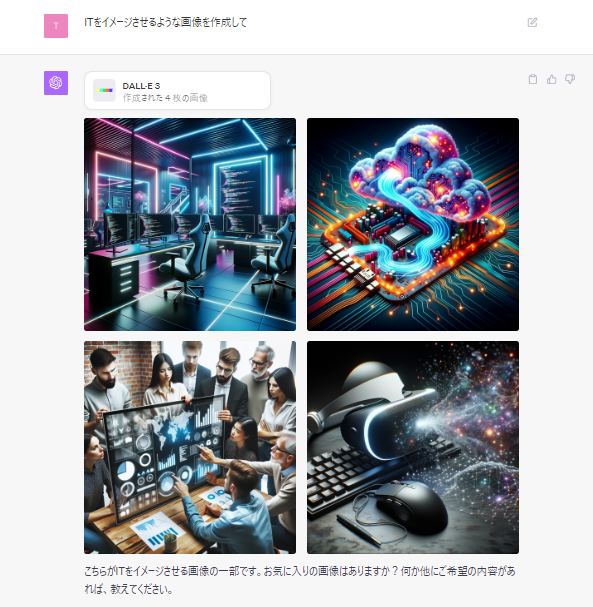
横長にする
プロンプトの中に「横長で」というような指示を入れると、横長の画像を生成してくれます。

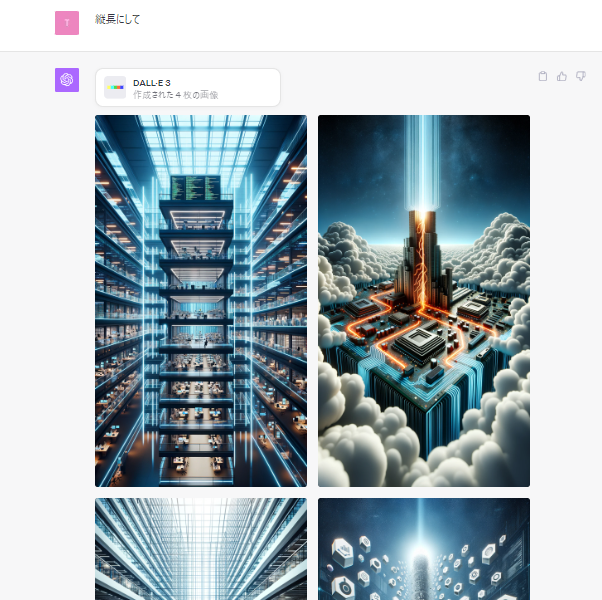
縦長にする
プロンプトの中に「縦長で」というような指示を入れると、縦長の画像を生成してくれます。
作成可能な縦横比について
作成可能な縦横比は、現在「1792px × 1024px」、「1024px × 1024px」、「1024px × 1792px」の3種類だけのようです。具体的にピクセル値を指定しようとしてもそのような回答が返ってきますし、逆に言えば、縦長、横長、正方形と指定するだけでこれらピクセル値での画像を生成してくれるということになります。
イラスト
「イラストで」と指示すれば、イラストにしてくれます。
テイストを指示する
「ポップな雰囲気で」など、テイストを指示すればそれに応えてくれます。ただし、このように端的に指示すると、極端にそのテイストに振ってくる感じがあります。
雰囲気の指定については細かく指示する必要があります。
ローマ字を入れる
「DX」という文字を入れてという感じで指示をすれば、文字も入れてくれます。
日本語文字は現時点不可
例えば「デジタルトランスフォーメーションという文字を入れて」という感じで指示をしても、次のようになってしまい、現時点、日本語を正しく表示することはできないようです。
中国語とかでもない、日本語風の文字を表示しようとするところは、生成AIの学習過程として個人的には興味深く見ています。外国人からすれば日本語ってこんな感じに見えてるんだな、という風に思いました。
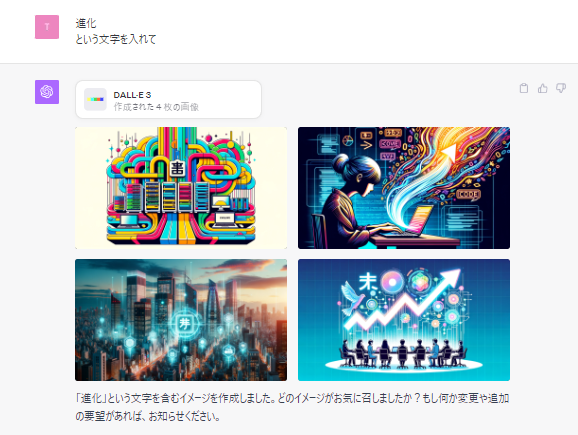
「進化という文字を入れて」とお願いした結果が次の画像です。なんだかハングル文字っぽいのも混じっているような?でもきっと、韓国語でもなければ中国語でもないですよね?「未」という存在する漢字を表示しているのは偶然な感じがします。
人、動物の描写
「公園の池の周囲を、笑顔で飼い犬の柴犬と一緒にランニングしている日本人女性を実写風に作成して」というプロンプトで作成された画像です。
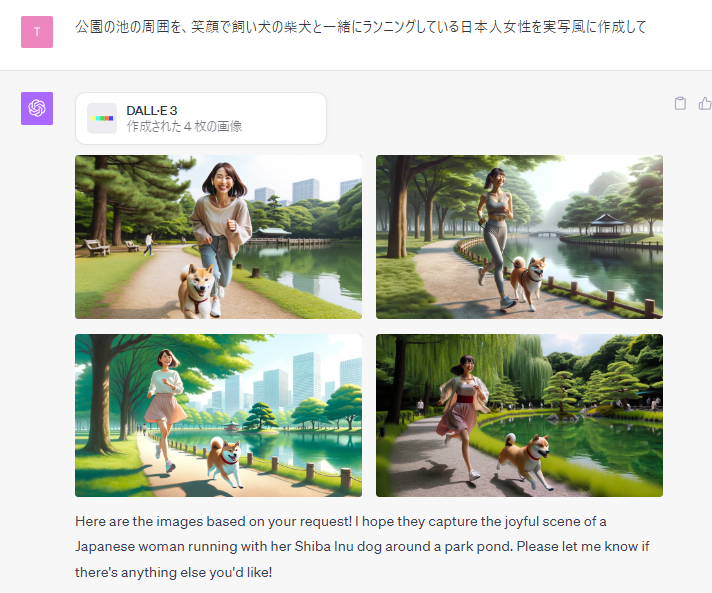
現時点、Midjourney(ミッドジャーニー)と比べると人は少し不自然な感じは残ります。動物の方がリアルな感じで描写してくれます。ただ、以前の画像生成AIは、手の数、足の数、指の数などが通常と異なるなどの精度だったのが、そういったレベルはクリアしています。
特定の画像に変更を入れる
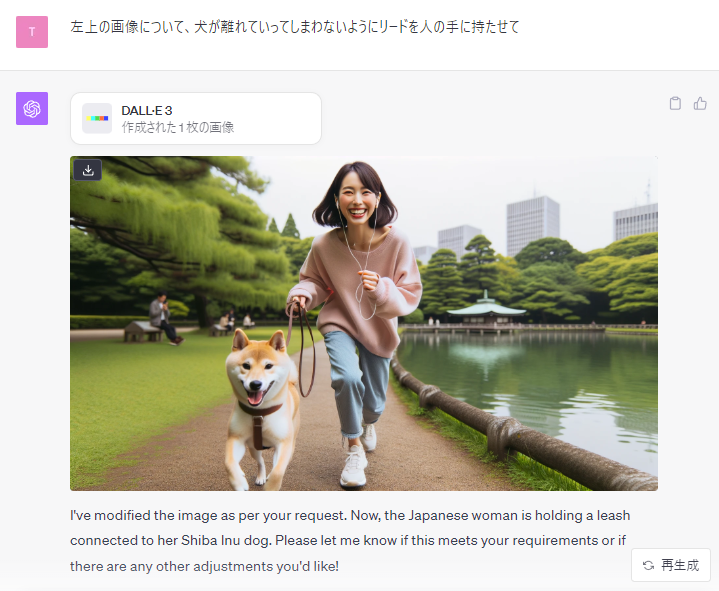
「左上の画像について、犬が離れていってしまわないようにリードを人の手に持たせて」というように指示をすれば特定の画像に対しての変更を入れてくれます。
なお、ここでは「左上」という表現で画像を指定しましたが、この表現の仕方だとたまにDALL-E3が解釈を間違うことがあるので、次のように表現した方が現時点では正確なようです。
- 左上:1番目の画像
- 右上:2番目の画像
- 左下:3番目の画像
- 右下:4番目の画像
「ちょっと人の姿勢がランニングしているにしては前かがみすぎて不自然なので、そこを直して。」と指示してみました。
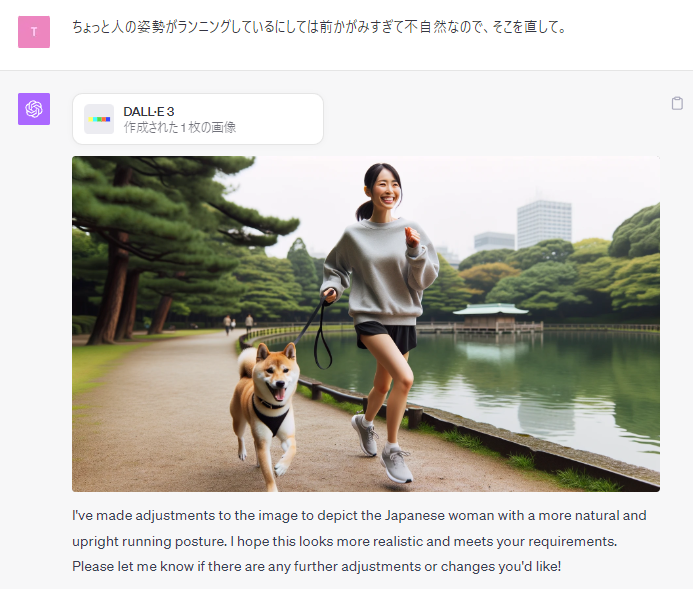
服装は変えてと言ってないのに、勝手に指示しているところ以外も変えられてしまうことが多いです。
この問題を回避して、特定の箇所だけ変える方法もあるのですが少し難しいので、後述します。
日本庭園風の公園は不自然なので、そこを変えてもらえるように「日本庭園風じゃなくて、日本の東京の住宅街によくあるような大きい公園にして」と指示してみました。
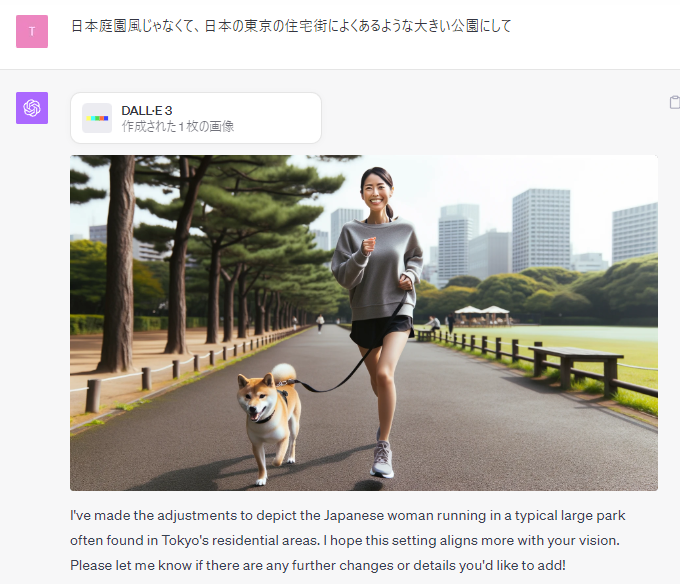
だいぶいい感じになってきましたが、やはり「松」が不自然なので、そこを変えてもらいました。
「松じゃなくてよく東京の道路脇などに植えられているような木にして。」
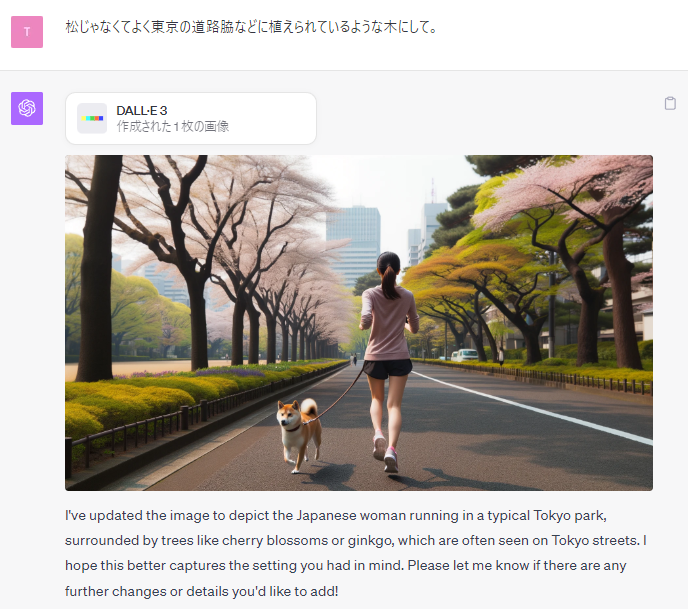
はい、こういうヘマをたまにします。
ツッコミポイント①:
人と犬の向きが逆。
ツッコミポイント②:
そんな大きな道路の真ん中走ったらダメ。
ツッコミポイント③:
いつのまにか公園の中にある池の周囲じゃなくなってるし。
アーティスティックなイラスト
「アーティスティックなイラストを横長で作成して」と指示した結果です。
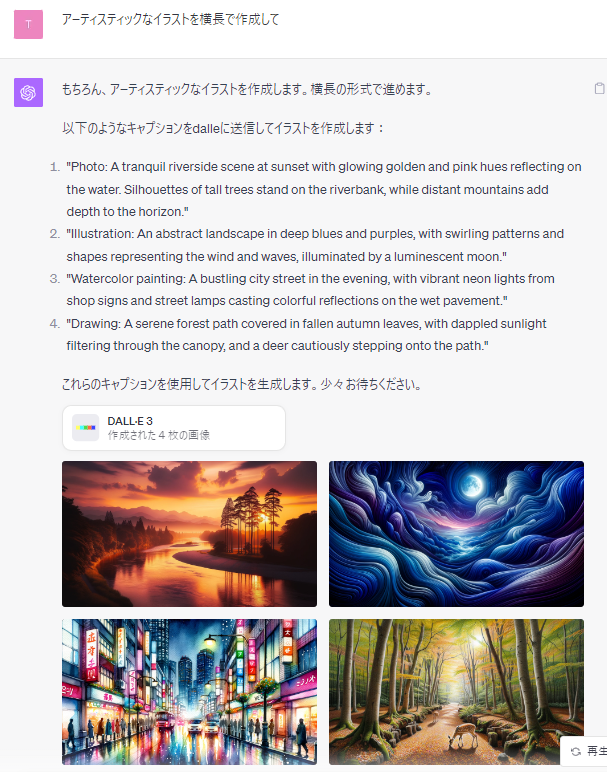
指示が抽象的すぎたようで、具体的な指示例を示してくれる(ただし英語)のと同時に、その結果の生成画像も示してくれました。
このように、アート的なもの、イラストの方がより実用的じゃないかと個人的には思います。
ロゴ
「花をモチーフにした事業者用のロゴを描いて」と指示してみました。
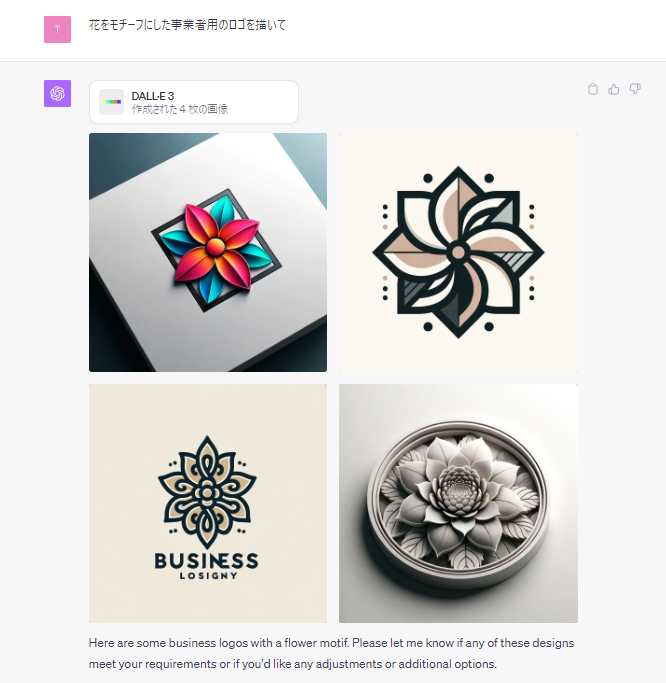
なかなかいいんじゃないですかね?指示を追加して好みに近づけていけば、ユーザーの満足いくロゴもできてしまうケースがあるのではないでしょうか。
DALL-E3で出力された特定の画像の特定の箇所だけ変更する方法
上記で、変更の指示をした場合に、指示をしてない場所まで変えられてしまうという問題があることをご紹介しました。これを回避し、特定の画像の特定の箇所だけを極力変えるようにする方法があります。
次のキャプチャ画面は、「幻想的な風景を横長で描いて」と指示して出力された2枚に対して、「2番目の画像のシード値は?」と尋ねたときのものです。
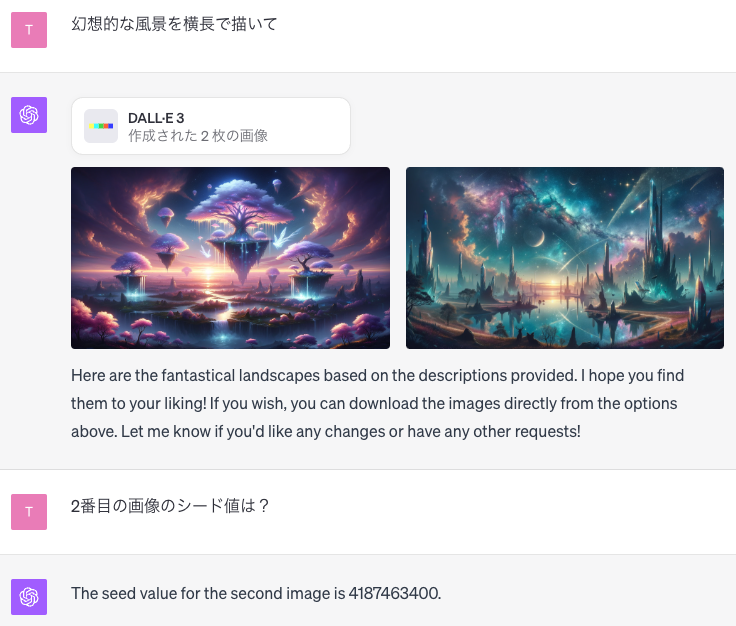
このように、DALL-E3が出力した画像の「シード値」を尋ねると番号を答えてくれます。
また、出力された画像をクリックすると、次のようにその画像を出力するのにDALL-E3が用いたプロンプトが表示されます。
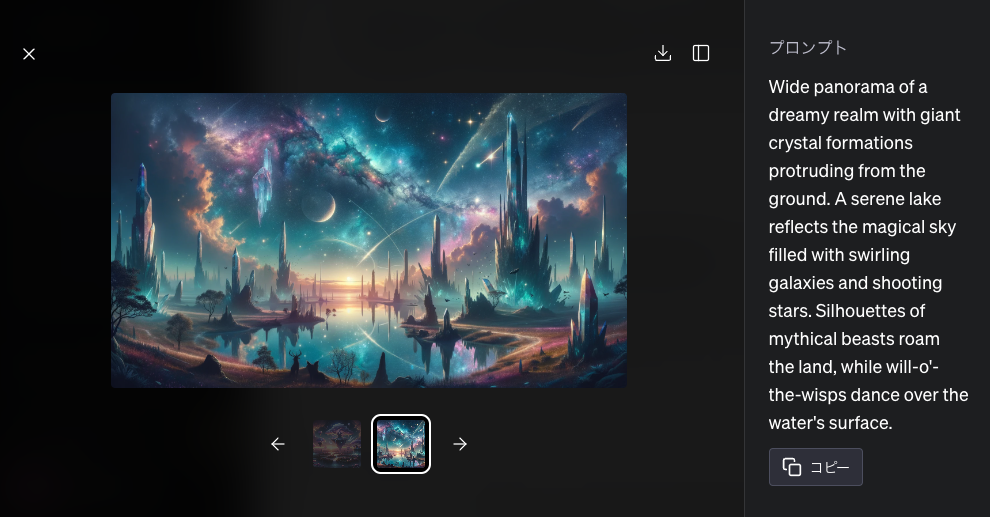
このプロンプトをコピーして、プロンプトとシード値をセットでDALL-E3に示すと共に、変更したいところだけ指示を加えます。
今回は、「男性と女性を一人ずつ、風景の中に描いて。」という指示を加えました。
DALL-E3は、ユーザーが指定したプロンプトを補間して画像を出力する機能があるため、プロンプトを変更しないようにするという指示も加えます。
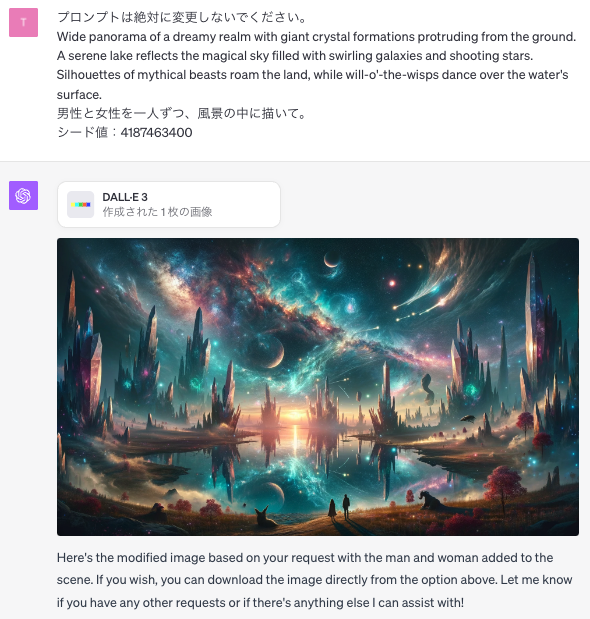
その結果がこちらで、元の画像の雰囲気や構図を崩すことなく、よく見ると下の方に男性と女性が一人ずつ描かれているのが分かります。
商用利用と著作権について
DALL-E3は利用規約でOpenAI社は権利を全てユーザーに譲渡するとなっています。
次のQ&Aページもあり、コンテンツポリシーと利用規約に基づけば販売などの商用利用が可能だと書かれています。
Can I sell images I create with DALL·E?
第3者の著作権を侵害しないようにというのはユーザー側が責任をもって配慮する必要がありますが、DALL-E3は、極力第3者の著作権を侵害しないように配慮されています。
例えば、「ドラゴンボールの悟空を描いて」と指示すると次のように著作権の問題を指摘するとともに、代わりになるような画像を生成します。

確かに、ドラゴンボールというよりはむしろ、ストリートファイターに近づいた感じですかね。
その他の制限
暴力的な内容、憎悪的な内容、アダルトは制限されています。そのような内容を指示すれば、拒否されるはずです。
DALL-E3の使い道
DALL-E3は様々な媒体向けに使えると感じます。工数の削減のみならず、品質の向上にも寄与するでしょう。例えば以下のような使い道が考えられます。
- 書籍向けのイラスト
- ファッションデザイン
- インテリアデザイン案の作成
- ゲーム開発のためのキャラクターデザイン
- 映画のコンセプトアート
- 広告ビジュアルの制作
- レストランのメニューデザイン
- 建築プロジェクトのビジュアライゼーション
- 記事のアイキャッチ画像などウェブサイトのグラフィックデザイン
- Tシャツやグッズのデザイン
- プレゼンテーション資料のビジュアル
- ミュージックビデオのアートワーク
- ポスターとフライヤーのデザイン
- ソーシャルメディアのコンテンツ
- ロゴとブランディンング
DALL-Eの社会的インパクト
DALL-Eに限らず、画像生成AIは2022年に広がり、現在ではすでに実用的に用いられています。特に、クリエイティブ産業に対する影響は重要なテーマとなります。
DALL-Eとクリエイティブ産業
DALL-Eの技術がもたらすクリエイティブ産業へのインパクトは計り知れません。アイデアの視覚化からデザイン工程の自動化まで、その可能性は無限です。
- アートとエンターテイメント業界では、DALL-Eは新たな視覚表現の探求を可能にし、シーン生成からキャラクターデザインまでを支援しています。
- 広告業界では、DALL-Eはキャンペーンのアイデアを視覚化し、その後のプロトタイピングをスピードアップする助けとなります。
- ファッション業界では、DALL-Eは新しい服のデザインを生成し、新しいトレンドを生み出す可能性を秘めています。
DALL-Eとクリエイターの関係
「ドラゴンボールの悟空を描いて」と言っても著作権の問題を指摘してくれたように、DALL-E3は著作権の問題をクリアするように訓練されてはいますが、結局のところAIが作成する画像は、学習の元になる作品があってこそです。人も何かしらのインプットがあってこそ作品を生み出すわけなので、やっていることは同じと言えば同じなのですが、自分の作品に似ていると感じる人も出てくるかもしれませんし、著作権の問題を抜きにしても、クリエイターにとってはDALL-Eは脅威とも捉えられるかもしれません。
DALL-E3はそのようなリスクを踏まえ、次のページから、クリエイターが指定の画像を学習過程から排除するリクエストができるようにしています。これをオプトアウトと呼びます。
なお、クリエイターの著作権を侵害してしまい、サービス停止になったサービスがすでに登場しています。議論と線引きはすでに進んでおり、DALL-Eは問題ない路線を進んでいるとは言えます。
AIと戦おうとするクリエイターは厳しい状況になっていく可能性があります。AIと戦うのではなく、AIを使いこなし、人にしかできないことを見出していくクリエイターが価値を高めていくのではないでしょうか。
AIライティングツールの記事においても似たようなことを私は述べています。
DALL-E3の画像生成過程
DALL-Eはどのようにして独自の画像を生み出すのか、解説します。
トレーニングデータとアルゴリズム
AIが画像を生成するステップは大きく分けて2つあります。1つ目は、AIに学習させるためのデータを集める過程。2つ目は、集めたデータに対してAIがアルゴリズムを適用して画像を生成する過程です。
トレーニングデータの選択と役割
DALL-Eはインターネット上の膨大な数の画像とその説明文をセットで、学習データとして使っています。このデータには地球上の多様な風景、アート作品、アニメーション、現象、事物など、様々な形状と色彩の画像が含まれています。
アルゴリズムの役割とその効果
学習データが準備されたら、次にアルゴリズムが適用されます。DALL-Eが使用するアルゴリズムは、ご紹介したようにテキストの指示文を理解して画像を生成するように設計されています。このアルゴリズムによる生成の結果には多様性が存在し、同じ指示でも異なる結果を生み出すことが可能です。そのためDALL-E3では4つの生成画像が示され、その中からユーザーの意図に合ったものを選択してもらい、必要に応じて修正をしていくという過程が想定されています。
生成モデルの設定と生成過程
次に、DALL-Eがどのように画像を生成するのか、その詳細について解説します。
モデルの初期設定
DALL-Eには、ChatGPTと同様、「Transformer」と呼ばれる汎用的なAIモデルが使用されています。このモデルは最初の段階では特別な知識は持っていません。しかし、モデルが学習データを大量に摂取することで、その領域の知識を確立し、画像生成の能力を向上させます。なお、モデルが学習する過程は、人間がオンラインで情報を得ていくときに似ています。「Transformer」のこの過程は一般的な機械学習の過程と同じですが、「Transformer」の特徴は、データの中における意味のある部分を見出して、不要な計算をしないというところにあります。それにより、画期的に精度が高まったと言われています。
なお、「Transformer」はOpenAI独自の技術ではなく、Googleが「Bert」と呼んでいる検索エンジン向けAIアルゴリズムにも採用されています。
生成物のレビューとフィードバックループ
画像の生成→評価→改善のプロセスを経て、生成された画像が最初にインプットされた指示に適合しているかどうか確認されます。つまり、ユーザーによる修正の指示は、DALL-Eの精度の向上に寄与しているものと思われます。この反復的なプロセスにより、DALL-Eは高度な画像生成能力を獲得してます。
適当に遊びで方針の定まらない指示を繰り返すのはDALL-Eの能力に悪影響を与えてしまうかもしれないので、やめましょう。
今後の展望と課題
DALL-E3の技術はまだ進歩段階にありますが、その社会へのインパクトは既に大きく、これからも増大していきそうです。倫理的な問題、著作権の問題はまだ議論が続きそうです。
AIによる倫理的な判断はまだまだ定まっていない領域です。例えば、AIが出力した結果が不適切な表現を含む可能性があります。その管理や制御は重要な課題です。ユーザーは、人だからこそ持つ倫理観を持って利用することが求められます。
DALL-Eの存在は、わたしたちの社会に対し新たな思考を促し、新たな視点をもたらしています。しかし、それをどう制御しどう活用していくかは、今後の大きなテーマとなりそうです。
まとめ
一躍、生成画像AIサービスの筆頭候補に躍り出たDALL-E3をご紹介しました。記事のアイキャッチ画像として十分使えるレベルにあると感じています。
AIライティングツール「BringRitera」では、DALL-E3よりもさらに使いやすく、かつより精度の高い画像生成AI機能追加を検討しています。
BringRiteraは、ChatGPTより10倍早く、かつ私のノウハウを注入することによって能力を最大限に引き出し、検索上位獲得記事を続々誕生させているAIライティングツールです。そちらもぜひ、ご期待ください。
「BringRitera」は無料で試せるので、ぜひお試しください!
