





AI(人工知能)
【徹底比較】画像・イラスト生成AIツールおすすめ9選
- 最終更新日:



画像生成AIは、指示文をもとに画像を生成してくれます。2023年10月に、OpenAI社による「ChatGPT Plus」でも「DALL-E3」という画像生成AIが利用できるようになり、この文章の横に配置している画像の背景はDALL-E3で生成したものです。
2024年8月にはBlack Forest Labs社によるFLUX.1がリリースされ、実写と見間違うほどの性能を誇っています。
もはや、画像生成AIの性能は凄まじく、利用しないという手は考えられないレベルにまで到達しています。
この記事では、現在存在する画像生成AIツールの主要なものをご紹介するともに、大元の技術として特に注目されていて、かつ私自身実用的だと考える「FLUX.1」「DALL-E3(ダリ3)」「Midjourney(ミッドジャーニー」「Stable Diffusion(ステーブルディフュージョン)」の4つについて、作成した画像をご紹介しつつ、性能や特徴を徹底比較します。
ご自身がどれを用いるかの参考にしていただければと思います。
メジャーなツールに比べて隠れた存在となっているリテラ(BringRitera)はFLUX.1[pro]、Stable Diffusionシリーズ、DAll-E 3の全てが使え、DALL-E 3だけが使えるChatGPTよりも安く利用ができて、使い方も簡単、断然おススメです。
画像・イラスト生成AIとは?
ChatGPTにより一躍、馴染みのある言葉となった「生成AI」。ChatGPTは文章を生成するのに対し、画像を生成するAIのことを「画像生成AI」と呼びます。「生成AI」と同様、現時点ではテキストによる指示文をベースにしたものが主流。画像と文章をセットに入力し指示できるものもあります。
「生成AI」は英語では「Generation AI」と呼ばれていて、「画像生成AI」は「Image Generation AI」と呼ばれています。
画像・イラスト生成AIの主要4ツール比較
まず画像・イラスト生成AIの主要4ツールについてその特徴を、実際に画像を同一プロンプトで作成し比較した結果を見た主観を含めてお示しします。総合的に見ても、リテラ(BringRitera)がおススメです。
| 項目 | リテラ(BringRitera) | ChatGPT | Discord | DreamStudio | X(旧Twitter) |
|---|---|---|---|---|---|
| 大元技術 | FLUX.1 [pro] Stable Diffusionシリーズ DALL-E3 | DALL-E3 | Midjourney | Stable Diffusion | FLUX.1 [Schnell] |
| 使い勝手 | ◎ 簡単、168種類テンプレ | 〇 文章を入力するだけだが、入力にコツが必要 | △ | △ | 〇 |
| 画像品質 | ◎ | ◎ | ◎ | 〇 高精細な人物を描画するには高いノウハウが必要 | 〇 FLUX.1の廉価版 |
| 著作権侵害の リスク(※) | 〇 | 〇 | △ | × | △ |
| 料金 | 〇 550円/月~ | × 20ドル/月 | △ 10ドル/月~ | △ 10ドル/1000クレジット | △ 980円/月 |
※ BringRiteraの採用技術でもあるDALL-E3は出力結果について、できる限り著作権を侵害しないように作られていますが、入力内容、および出力結果の著作権保護はユーザー自身の責任となります。
画像・イラスト生成AIツール
大元の技術は後でご紹介する主には上記の4つが使われているのですが、ツールとしてはどのようなものがあるかご紹介します。
プロンプトは、指示文の理解度も見るため、やや複雑な内容として
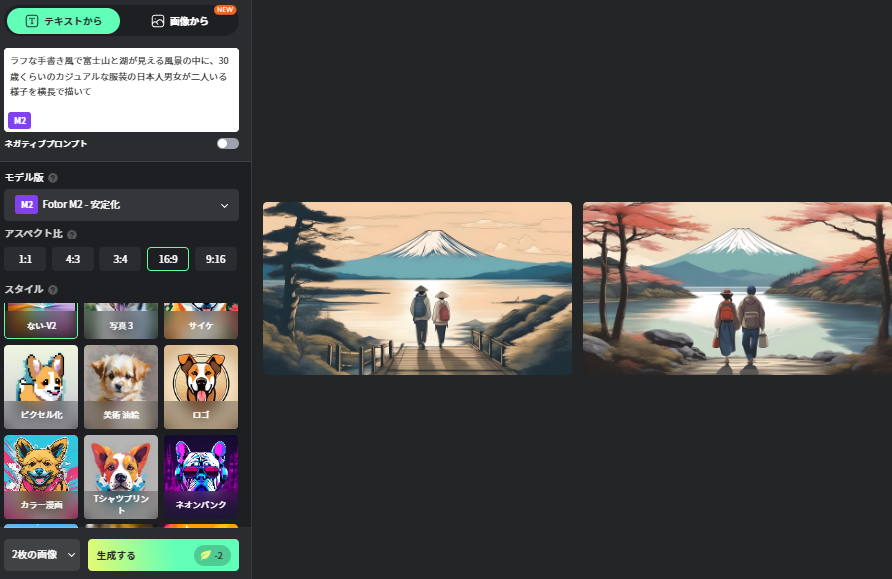
「ラフな手書き風で富士山と湖が見える風景の中に、30歳くらいのカジュアルな服装の日本人男女が二人いる様子を横長で描いて」
で統一します。
リテラ(BringRitera)
次の画像はリテラ(BringRitera)のFLUX.1 [pro]を利用して出力した画像です。リアルすぎてAIだと伝わりづらいですよね。

BringRiteraは、FLUX.1 [pro]、Stable Diffusionシリーズ、DALL-E3の中からモデルを選ぶことができて、月額550円(税込)~で利用できます。スタイルが14種類から選べるなど使い方も非常に簡単、どのAIモデルでも共通の操作。断然おすすめのツールです。
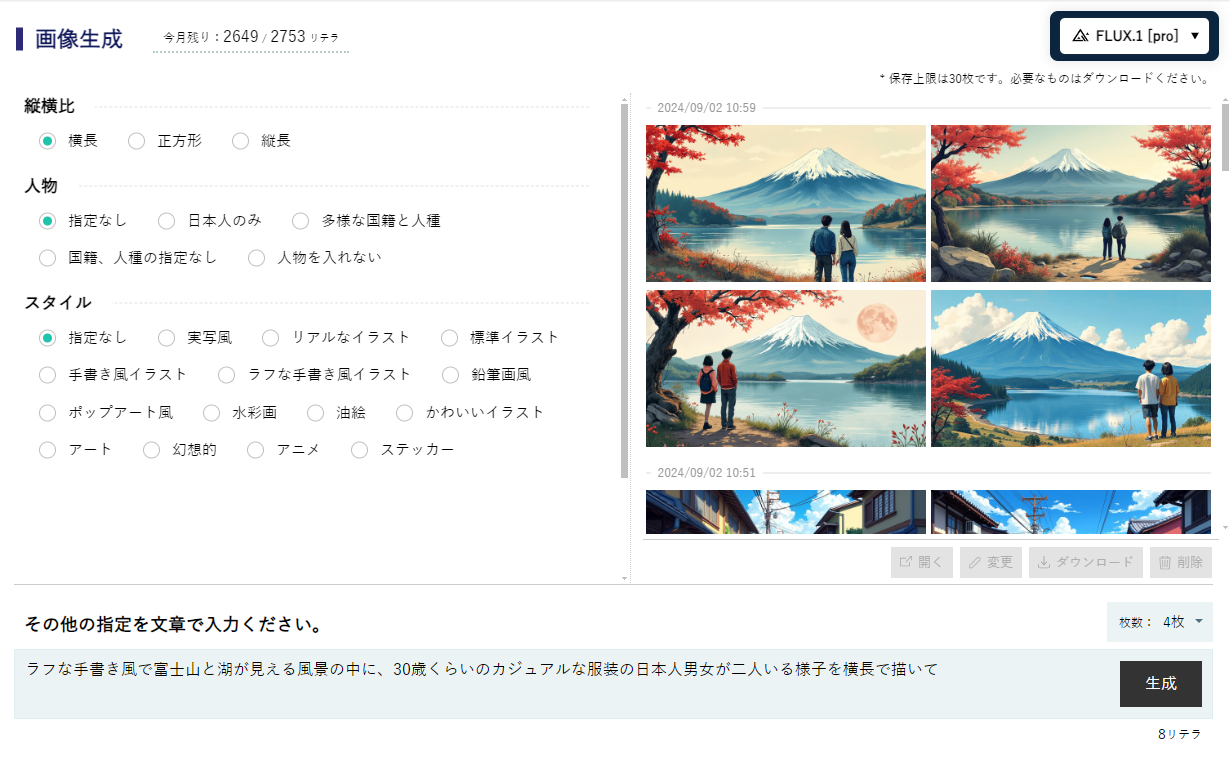
ChatGPT Plus
ChatGPT-Plusは月額20ドルで、ChatGPTと同じく開発元がOpenAI社のDALL-E3により画像を生成します。さすがの理解力と描画力です。
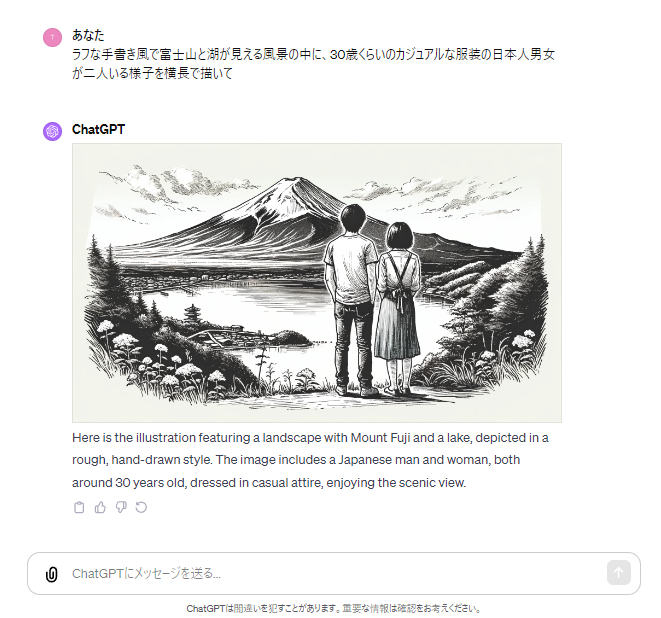
Bing Image Creator
Bing Image Creatorは、MicrosoftのブラウザであるEdgeを利用している場合のみ利用できるツールで、OpenAI社のDALL-E3を利用しています。
無料で利用できますが、商用利用はできないので、その点はご注意ください。
一度に4枚作成してくれます。ただ縦横比は正方形しか対応してない感じでしょうか。
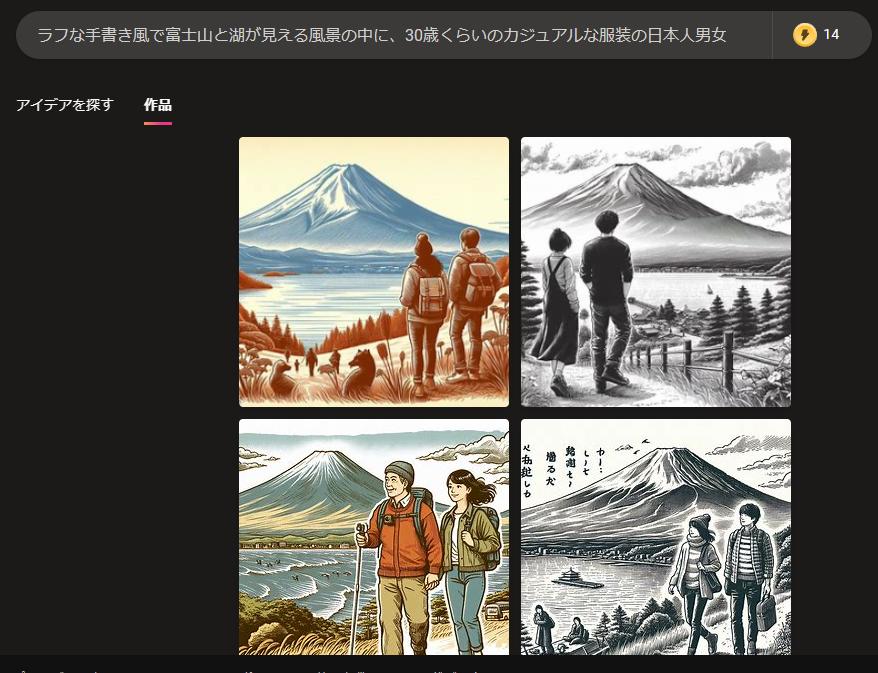
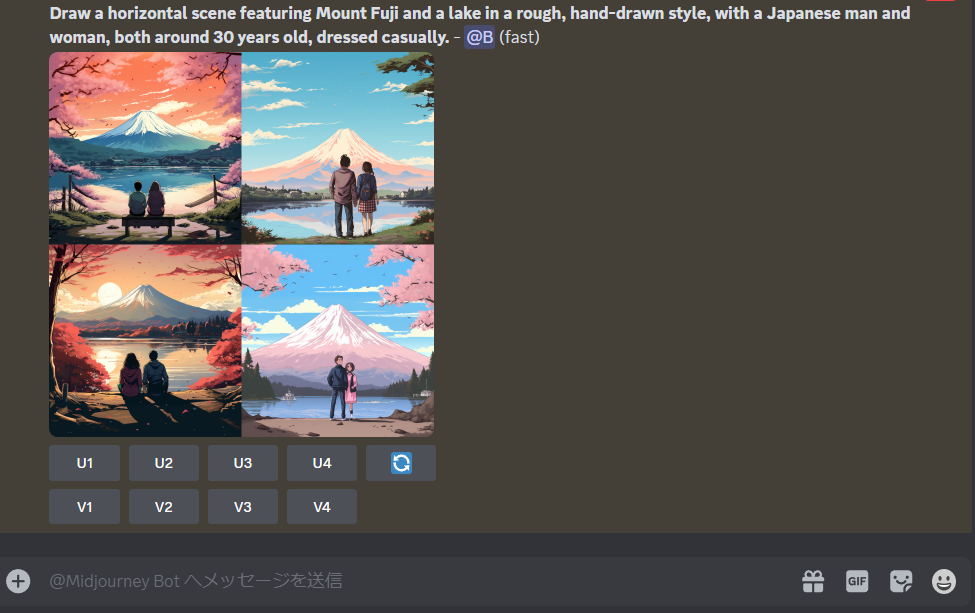
Discord
Discordは、ちょっと使い方で敷居が高いですが、Midjourneyを無料で使うことができます。日本語のプロンプトも受け付けますが、日本語だと精度が悪いので次の画像は、ChatGPTに英訳してもらった英文「Draw a horizontal scene featuring Mount Fuji and a lake in a rough, hand-drawn style, with a Japanese man and woman, both around 30 years old, dressed casually.」と入力しています。
SeaArt
SeaArtはシンガポールに本社がある「STAR CLUSTER PTE. LTD.」のサービスで、Stable Difusionが使われています。無料で一定使えます。
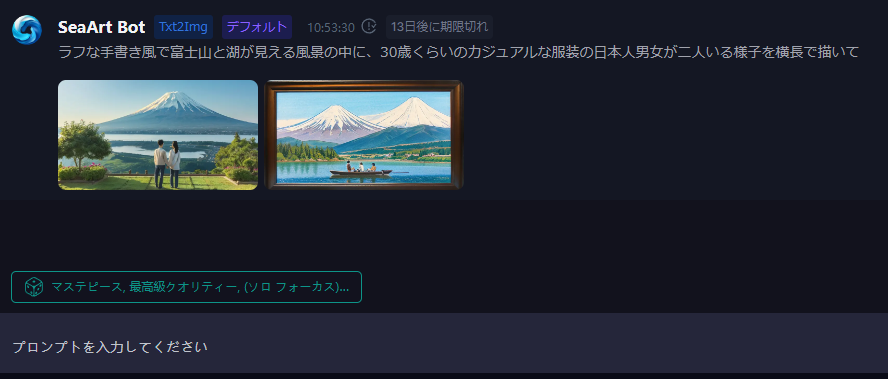
DreamStudio
Stable Difusionが使われているツールの中でも有名なのがDreamStudioです。日本語も受け付けるのですが、今回のプロンプトだと複雑すぎるのか受け付けられず、英語で「Draw a horizontal scene featuring Mount Fuji and a lake in a rough, hand-drawn style, with a Japanese man and woman, both around 30 years old, dressed casually.」と入力した結果です。
顔の描画精度は低いです。
Canva
デザインツールのCanvaでは無料で画像生成機能もあります。見た感じ、私の推測ですがDALL-E2(DALL-E3の前のバージョン)じゃないかなという感じがします。DALL-E3と出力の画風は似てますが、男女2人になってなかったり、人の顔などの描写の精度が低かったりします。


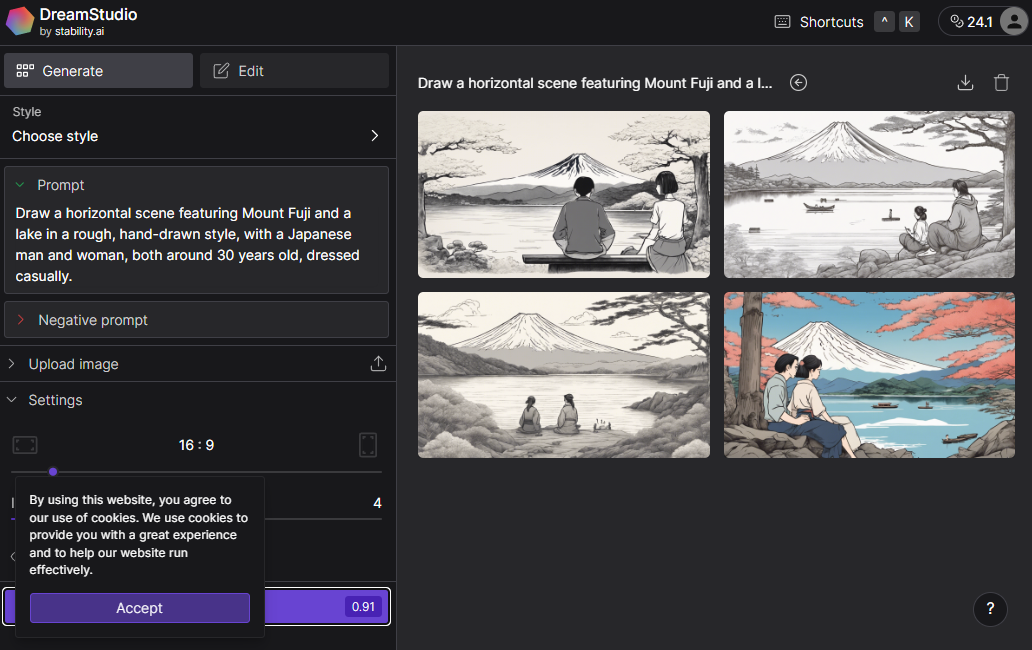
Adobe Firefly
PhotoshopやIllustratorでお馴染みのAdobeが提供するサービスです。発表当時と比べてかなり進化している感じがします。
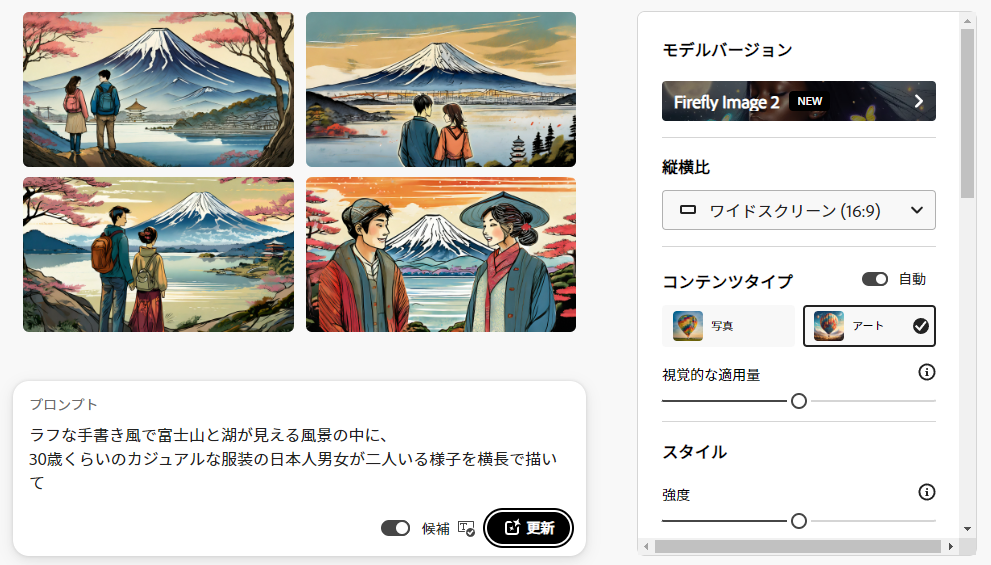
MyEdit
MyEditは写真編集や動画編集のソフトを開発・販売しているCyberLinkによるツールで、一定量無料で画像生成機能が使えます。プロンプトの理解度は高いですね。描画の質は好みにもよるところでしょうか。
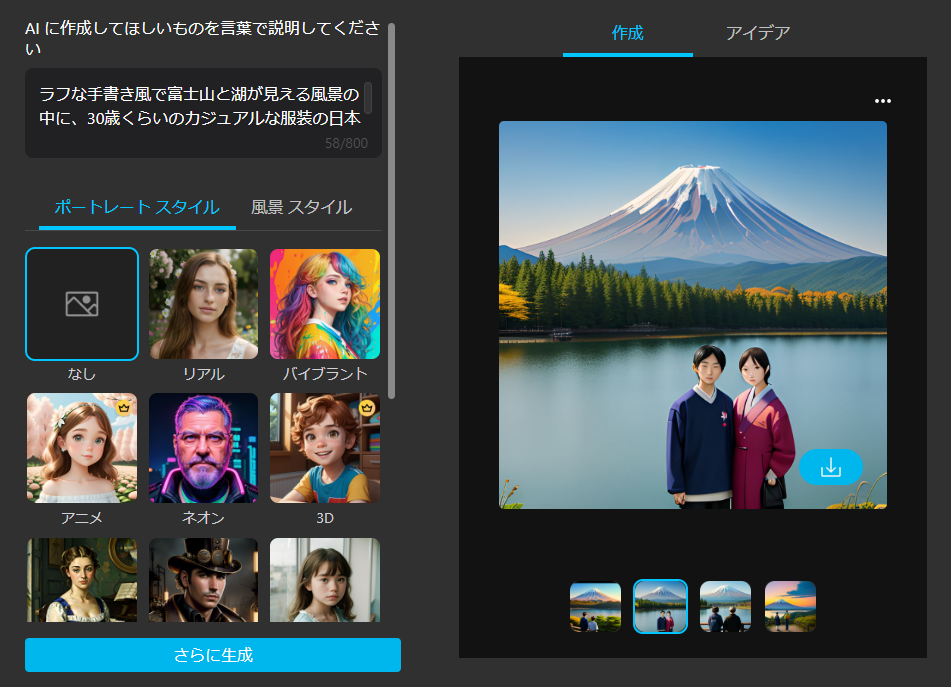
foter
fotor(フォター)はEverimaging Science and Technology Co., Ltdが開発している画像編集などができるソフトで、少しですが無料で画像生成も可能です。アニメ風が得意かもしれません。
画像・イラスト生成AIの大元技術
画像生成AIツールはこのように様々存在しますが、使われている元の技術は同じであるものもあります。例えばMicrosoftのBingにはOpenAI社のDALL-Eが用いられていますし、デザインツールであるCanvaにもおそらくDALL-Eが用いられていると私は推測しています。
ツールによって使い勝手は異なりますが、大元の技術に着目して考えた場合に、現時点で有力な候補として以下の5つが挙げられます。
| サービス名 | 開発元 | 開発元について |
|---|---|---|
| FLUX.1 | Black Forest Labs | Stable Diffusionの元開発者が設立した会社。 |
| DALL-E3 | OpenAI | 2015年にイーロン・マスク氏らによって設立。 その後、Microsoftの巨額投資を受けるなどして成長。 ChatGPTの開発元でもある。 DALL-Eの最初の発表は2022年1月。 |
| Midjourney | Midjourney | 2022年7月にオープンになった。Leap Motionの創業者であるデビッド・ホルツ氏が開発。 |
| Stable Diffusion | Stability AI | 2022年8月にオープンになった。無料で利用できて、オープンソースでもあるという特徴がある。 |
| Imagine/Parti | Googleは2022年に入ってからまずImagineを、続いてPartiを発表。それぞれ異なるアルゴリズムが用いられている。SGEで画像生成できる試験が始まっている。 | |
| Adobe Firefly | Adobe | Adobeは2023年3月にAdobe Fireflyを発表、2023年6月にはPhotoshopやIllustratorで利用できる機能がリリースされた。著作権保護に厳格に対面しているという特徴がある。 |
このように、画像生成AIの実用化は2022年に始まったばかりなので、今後も新たな何かが登場するかもしれませんし(2024年8月、FLUX.1が登場したので追加しています)、この中でも何が主流になるかはまだ何とも言えません。
現時点では、品質面、ユーザー数の両側面で見ても、特に「FLUX.1」「DALL-E3」「Midjourney」「Stable Diffusion」の4つが抜きん出ている状態だと言えます。
「FLUX.1」「DALL-E3」「Midjourney」「Stable Diffusion」の比較
「FLUX.1」「DALL-E3」「Midjourney」「Stable Diffusion」の4つについて、同じプロンプトでどのような画像が生成されるかを比較して示します。
「FLUX.1」は「リテラ(BringRitera)」を、「DALL-E3」は「ChatGPT Plus」を、「Midjourney」は「Discord」を、「Stable Diffusion」には「DreamStudio」をそれぞれ用いています。
横長の画像で統一して比較します。ChatGPT Plusで用いるDALL-E3はすべてをテキストで指示するので、プロンプトの最後に「縦横比は横長にして(make it wide.)」と加えています。Midjourneyは指示文の最後に「–ar 16:9」のようにコマンドを入れる必要があるようなので、そうしました。
また、DALL-E3は一度に4枚提示していた時もあるのですが、本記事執筆時点ではサーバー負荷が高まっているためか一度に作成できる上限が2枚にされているので、「他のを2枚追加して(add 2 slides.)」と指示を加えた上での計4枚を示します。
幻想的な風景
まずは、クリエイティビティが試される幻想的な風景で試しましょう。以下のプロンプトを実行しました。
元の日本語文:
海と陸が入り混じった世界の中心に、天を向いて日本人の男性が一人たたずんでいる幻想的な風景を描いてChatGPTによる英訳文:
A fantastical landscape where the sea and land intertwine, with a Japanese man standing in the center, looking up at the sky.どうして日本語と英語の両方かというと、このあとお見せするように、Midjourneyが日本語だと極端に品質が落ちるためです。
ちなみに、具体的なイメージを持ってこのプロンプトを考えたわけじゃありません。ある程度抽象的な指示に対してどう応えてくれるのか、というのもひとつの視点としてあります。
FLUX.1 [pro]
さすがのクオリティです。少し他と比べると暗くてぼんやりした感じになるのはFLUX.1が劣るところだと私は思ってます。好みにもよると思いますが。

DALL-E3
まずは日本語の指示で。ふむふむ。この中なら1枚目がいいかな。


次に英語の指示文で。表現は変わってますが、理解(方向性)は変わってない感じがしますね。


Midjourney
まずは日本語の指示文。
・・ん??

次に英語の指示文。このように日本語と英語で全く品質が異なります。
どうやらMidjourneyは日本語だと理解の精度が低いようです。日本語を内部的に英訳すればいいだけじゃないのかと思ってしまうんですが・・そこの精度が低いようですね。

Stable Diffusion
まずは日本語の指示文。

次に英語の指示文。
日本語と英語の違いによる品質の違いは見られませんね。Stable Diffusionは多様性をもたらすという感じはせず、悪く言えば、あまり変わり映えがしません。好みのテイストであれば、その中でもいくつかパターンを作ってもらえるという点で良さそうです。

幻想的な風景の比較結果まとめ
まずここまでで、Midjourneyは日本語と英語の精度が全く違い、DALL-E3とStable Diffusionはその点はクリアしているということが分かります。
幻想的でメカニカルな生物
次に幻想的な中にメカニカルな生物を描いてもらいます。先ほどの試行の時点で、Midjourneyは日本語の指示文だとまだ使いものにならないということが分かりましたので、この後からはすべて英語で統一します。なお、日本語で考えた文章をChatGPTに英訳してもらったものを使いますので、全て元の日本語も示します。
元の日本語文:
幻想的な風景にメカニカルな幻想的な生物がいる風景を描いてChatGPTによる英訳文:
A fantastical landscape where the sea and land intertwine, with a Japanese man standing in the center, looking up at the sky.FLUX.1 [pro]

DALL-E 3


Midjourney

Stable Diffusion

幻想的でメカニカルな生物の比較まとめ
画像生成AIは幻想的な世界を描くのが得意な感じがします。どれも素晴らしく、あとは好みでしょうか。
メカニカルでクールなロボット
元の日本語文:
巨大隕石に立ち向かう、メカニカルで大きく、クールなロボット。地球を救うシーン。ChatGPTによる英訳文:
A large, mechanical, and cool robot facing a massive meteor. A scene of saving the Earth.FLUX.1[pro]

DALL-E3


MidJourney

Stable Diffusion

メカニカルでクールなロボットの比較結果まとめ
画像生成AIはロボットを描くのも得意だと思います。
4つそれぞれで、指示文の意味の理解度の違いが出ていると思います。
ただDALL-E3の1枚目は、隕石衝突に間に合ってない感じもしますね(笑
ITをイメージさせるやつ
次に、よくウェブサイトなどで用いられそうなITをイメージさせる画像を作ってみてもらいましょう。あえて抽象的な指示にしてみます。
元の日本語文:
ITをイメージさせる画像を作って。ChatGPTによる英訳文:
Create an image that evokes the concept of IT.FLUX.1 [pro]

DALL-E3


Midjourney

Stable Diffusion

ITをイメージさせる画像の比較結果まとめ
これに関してはFLUX.1とDALL-E3の圧勝ではないでしょうか。指示の理解度から違うのかもしれませんね。FLUX.1は、ボケ味を活かした画像を生成するのが得意だと感じます。Stable DiffusionとMidjourneyも、指示文を具体的にすればイメージに近づくかもしれませんが、仮にそうだとしても、端的な指示で簡単にイメージ通りのものが作れる方が良いですね。
油絵風
次に油絵風を試します。
元の日本語文:
夕日が水面に綺麗に映った大きな湖の風景を油絵風に描いて。ChatGPTによる英訳文:
Paint a scene in the style of an oil painting of a large lake where the setting sun is beautifully reflected on the water's surface.FLUX.1 [pro]
割とリアルに描いた油絵という感じです。

DALL-E
いい感じですが、油絵風という感じはしないかな?


Midjourney
綺麗ですね。

Stable Diffusion
油絵風な感じしますね。

油絵風の比較結果まとめ
油絵風という指定に対してはStable Diffusionが最もそれらしく、次にMidjourneyでしょうか。DALL-E3の出力結果はCGである、という印象が他と比べると強い感じがします。
水彩画風
次に水彩画風です。
元の日本語文:
お花畑で笑顔の日本人少女が蝶々を追いかけている風景を水彩画風に描いて。ChatGPTによる英訳文:
A Japanese girl with a smile chasing butterflies in a flower field, depicted in a watercolor painting style.FLUX.1 [pro]
人の描写がバラエティに富んでいますね。

DALL-E3
DELL-E3は、続けて修正の指示ができる仕様になっているからか、色んなテイストを示そうとする傾向です。


ちょっと趣旨からずれますが、続けてmore artistic, pleaseと打ってみたら次の通りです。

DALL-E3はテイストを指定すると、極端に振る感じがあります。
Midjourney
人は全部同じモデルで描いてるかな?

Stable Diffusion
水彩画風ですね。

水彩画風の比較結果まとめ
個人的には、Stable Diffusionの描写が一番イメージに近かったのですが、少女の年齢のイメージが近かったというのが大きな理由としてあります。ただMidjourneyが描いた少女の年齢層も、確かに「少女」と表現される年齢層だと言えます。ここでは、少女の年齢まで指定するべきだったということを感じました。
画像生成を使っていると、いかに言語というのがすれ違いを生みやすいかということを実感できますね。
アートなイラスト
次にアートなイラストを指示してみます。
元の日本語文:
架空の生物が人を囲って集う様子をアートなイラストで作成して。ChatGPTによる英訳文:
Create an artistic illustration of fictional creatures gathering around a person.FLUX.1

DALL-E3


Midjourney

Stable Diffusion

アートなイラストの比較結果まとめ
好みが分かれそうですね。DALL-E3はやはり多様性があって面白いですが、Midjourney、Stable Diffusionそれぞれのテイストと似たようなものを描いてくる気配はないですし。
個人的には一番イメージに近かったのはStable Diffusionです。
クールなイラスト
次にクールなイラストを指示してみます。
元の日本語文:
男子バレーボールの世界レベルのエースアタッカーが高く飛んで打つ瞬間をクールなイラストで描いて。ChatGPTによる英訳文:
Create an artistic illustration of fictional creatures gathering around a person.FLUX.1 [pro]

DALL-E3


Midjourney

Stable Diffusion

クールなイラストの比較結果まとめ
クールなイラストというテイストの指示に対してはどれも対応を見せてくれてますが、ここにきて、表現の精度が急に下がった感じが・・。なんの競技?というやつが多いですね。
そんな中、FLUX.1 [pro]が最もリアルに描写できていると思います。FLUX.1はリアルな描写が得意です。
DALL-E3の1枚目は笑いました。DALL-E3の2枚目が一番品質が良いと言えそうでしょうか。ただ微妙に空振りしそうになってますし、ネットの張られ方が格闘技のリングみたいになってますね。色々ツッコミどころが満載です。
バレーボールの画像の情報が足りないのですかね・・。元バレーボールプレーヤ―の私としては悲しい。
かわいいイラスト
次にかわいいイラストを指示してみます。
元の日本語文:
子猫3匹が寄り添って寝ている様を、5歳くらいの女の子が見つめるところをかわいいイラストで描いて。ChatGPTによる英訳文:
Create a cute illustration of three kittens snuggling together and sleeping, while a 5-year-old girl watches them with fascination.FLUX.1 [pro]

DALL-E3


Midjourney

Stable Diffusion

かわいいイラストの比較結果まとめ
「かわいいぃ~」という声が聞こえてきそうなイラストが揃いましたね。
指示文の内容を一番理解しているのはDALL-E3ですよね。イラストの品質はStable Diffusionが個人的には好みです。でも頭部と胴体の毛色が違うという新種が生まれてますね(笑
人物の実写風
さて、気になっている方が多いであろう、人物の実写風の精度を見てみましょう。以下の指示文で作成したところ、見ての通りフォーマルなものばかり出てきたので、気になって「Their fashion is casual.」という一文を加えた4枚、計8枚ずつを紹介します。
元の日本語文:
東京のお洒落なカフェで食事をする日本人カップルの美男美女をリアルに描いて。ChatGPTによる英訳文:
Create a photo of a handsome Japanese man and a beautiful Japanese woman, both as a couple, dining in a fashionable cafe in Tokyo.※ChatGPTはリアルに描くというのを「realistic illustration」と表現しましたが、そうするとイラスト風になるので、「photo」に変えてます。
FLUX.1 [pro]


DALL-E3




Midjourney


Stable Diffusion


人物の実写風の比較結果まとめ
画像生成AIを紹介する記事はどこもかしこも美女だらけ、という中でイケメンも描かせてみましたが、いかがでしょうか?新鮮じゃないですか?
人物の実写は、2024年8月時点ではFLUX.1が最もリアルになります。その前はMidjourneyが最もリアルでした。DALL-E3は不自然さはないですが、AIによるものだという感じはします。ただ、「あえてそれでもいい/むしろその方が良い」という考え方、用途もあるかもしれません。
Stable Diffusionは目元が特に不自然になりがちな結果になりました。Stable Diffusionはオープンソースで、用いるモデルによって描かれる内容が異なるというものです。美女が精度よく描かれた事例をよくみかけるので、モデルを変えればそうなるのか、SeaArtというモデルを変更できるサービスで検証してみました。結果、このように人物以外の描写指定もプロンプトの中に入ると、結局のところ、顔が歪んでしまうというのが現状のようです。
アニメ風
最後に、日本のアニメ風というのを指示してみます。
元の日本語文:
日本のアニメ風に、京都の街並みを描いて。ChatGPTによる英訳文:
Create an illustration in the style of Japanese anime depicting the cityscape of Kyoto.FLUX.1 [pro]

DALL-E3


Midjourney

Stable Diffusion

日本のアニメ風の比較結果まとめ
FLUX.1が安定しています。Midjourneyの1枚目も私のイメージには近いですが、いかがでしょうか。
ただどれも、品質は高いですよね。
画像・イラスト生成AIの技術について
「画像・イラスト生成AI」も、「生成AI」と用いている技術の元としているものは同じです。いわゆる機械学習です。機械学習の基本的なモデル(考え方)は、1950年頃から存在したものです。近年急速に機械学習が発展している背景には、コンピューターの性能向上もありますが、2017年に発表されたTransformerと呼ばれるアルゴリズムの寄与が大きいです。Transformerは、機械学習の過程における元データの分析段階で、無駄な情報を排除することで分析の精度、性能を大幅に向上させました。ChatGPTも、DALL-E3も、このTransformerを元に開発されています。
Googleが2018年に検索エンジンに用い始めたBERTと呼ばれるAIアルゴリズムも、Transfomerが使われていたりします。

機械学習は、大量のデータを元に意味、アウトプットを特定していくというものです。
赤ん坊は、聴覚から入ってくる情報とともに、視覚的な情報、前後の文脈など様々な情報をもとに言葉の意味を判断し覚えていきます。自分の顔を見ながら名前を呼び続けられることで、その名前は自分のことなのだと理解しますし、「こっちにおいで」と手前に呼び寄せるような手ぶりと共に言われ続け、近づいたら喜んでもらえるということを判断し、「こっちにおいで」はそういう意味なのだと理解します。「こっち」「に」「おいで」というそれぞれの意味の分解も、そういう過程の中で行われていくでしょう。

一方で生成AIの文章の学習は、テキスト情報のみで行われていますので、学習の元とする情報の種類は人間と異なりますが、学習の過程は人間と似ていると言えます。
「こっちへおいで」
「こっちにおいで」
これら両方同じ意味だということも、大量のテキストデータを元に、テキスト同士の前後関係から学習するわけです。機械学習には「教師あり」「教師なし」の2種類あり、人により教育されるケースもあります。
画像生成AIの学習は、大量の画像データを元に行われています。
有名人の名前でGoogleで検索すればその人の顔写真がGoogleの検索結果に出てきます。それは、Googleがその人の名前と、その人の顔との関連性を見出しているからに他ないでしょう。
まとめ
これは試行が尽きませんね。3社のモデルが使えるリテラ(BringRitera)で色々試してみてください。
現時点、画像生成AIは実写風での利用よりも、特にイラストやアーティスティックな作品の生成の品質がより高いと言えそうです。
ただし、Stable Diffusionは先述の通りモデルや指示方法にもよります。
頑張れば無料で使えるのはStable Diffusionです。ただし、かなりのITリテラシー、高いマシンスペックが求められます。
出力される画像の品質に関して、総合的にはFLUX.1[pro]が現時点最も優れているのではないでしょうか。
DALL-E3は多様なものを描き、その中からユーザーの好みを選んでもらうということと、そこから修正をしてもらうというプロセスまで考えられていると思います。
また、指示の種類にもよりますが、総合的に指示文の理解度が最も高いのも、DALL-E3のような感じがします。
いずれのサービスも、まだまだ多様性は増し、実写風のリアリティさも進化するのだと思います。
ご自分の好みや使い勝手などを踏まえて、選ぶのが良いかと思いますが、選定の参考になったなら幸いです。
